近两个月由于个人处于新环境、新项目的适应阶段,没怎么提笔写些文章。中间有好几个想法想记录下来分享,但受限于没有很好的时间段供自己总结思考(也可以总结为间歇性懒癌和剧癌发作),便啥也没有更新。借这个周末闲适的下午和明媚的阳光,决定把近来项目上的CI/CD(持续集成/持续交付)策略以及git分支模型和以前的项目做一下分析比较,希望对各位有所帮助,也能有所思考,尤其是那些期望搭建项目部署流水线或者想了解git分支模型的开发、运维人员。
背景
废话不多说,由于近期做了N次release,所以对自己目前所处的新项目的部署方式有了一定的了解。为了方便,本文就叫该项目为A项目吧。发现A项目的部署方式和我之前接触的TW“传统”CI/CD策略差异比较大(在TW,几乎每个项目都有持续集成/持续交付流水线,如果你对它们的概念还不是很清楚,建议阅读持续交付这本书,将对你梳理整个交付流程帮助巨大)。
关于A项目的背景,受客户保密协议的限制,我只能透露几点。A项目所属公司为国外某大型电信运营商,主要内容为用户账户自服务平台。该平台涉及诸多内外部服务,如认证、订单跟踪、短信认证等等,数量总数在三十多个左右,而每个服务都是一个独立的子系统,有独立的代码库、独立的机器实例(AWS EC2 实例)用于运行,以及一套独立的jenkins job用于自动化构建和部署(即我们接下来谈的内容)。当然,这也是为什么A项目想往微服务架构迁移的主要目的。
接下来,让我剥去诸多项目的其他内容,仅仅讨论一下它的CI/CD策略,也可以说是它的构建、部署方式。
A项目的CI/CD策略
千言万语还是不及一张图(作者小学美术数学老师教的,望见谅):
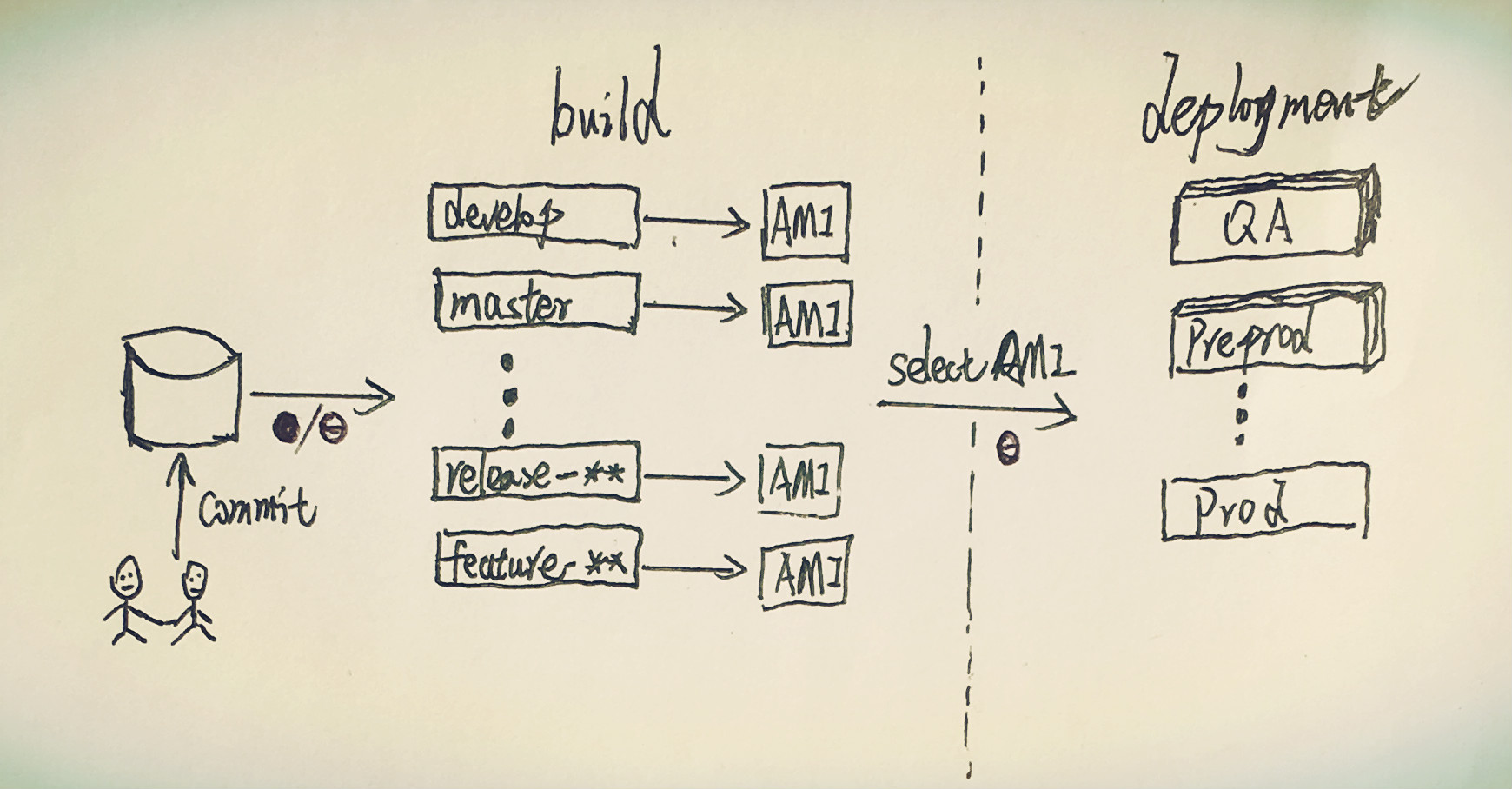
上图,为一个独立子项目(如背景中所说的某个服务)在其jenkins里面的任务(job)结构图,主要有两种自动化任务,build和deploy:
- build - 即构建任务。developer在代码仓库(这里是github上某个私有仓库)某个分支上提交了代码后,自动或者手动地被触发。它会根据对应的分支,如develop、一些feature分支或release分支上,而在其对应的任务上构建、运行各层测试以及生成对应的AMI镜像。
- deployment - 即部署任务。该任务需要人工手动点击触发,因为很多时候需要改动一些部署配置,比如说选择刚刚build任务生成的哪个分支的那个AMI文件以及更改一些endpoint的值。它会根据你需要部署的环境,利用自动化部署工具chef,基于对应的AMI镜像生成对应的EC2实例、ELB等等资源,让我们的服务在对应的环境中正式地运行起来(当然也伴随着销毁旧的资源的过程)。这个过程如果目标环境是prod的话,其实就是真实的发布了。
这用在该项目组中几乎所有的以服务为单位的子系统之上,也就是说,我们有将近三十套左右类似这样的jenkins任务。
需要说明的是,上图中的黑色圆圈、黑色圆圈加横线和黑色空心圆圈分别代表完全自动化、需要手动更改配置后点击触发 和 需要手动点击出发 三种情况,即如下图所示:

这样的方式有如下几个特点:
- 以分支和环境为中心 这种策略在构建时以分支(branch) 来区分构建的产物,如果你的工作模式是在各个不同的分支上开发且测试的话,你可以基于分支的相互独立的进行对应的部署和测试。举个栗子,如果你基于feature1分支构建生成了一个AMI镜像,然后你基于该镜像部署它到qa-1环境中,然后同样的将feature2分支部署到qa-2环境中,然后测试人员就可以同时在两个环境测试不同的功能。
- 保持了CI/CD中的自动化 构建和部署实际上还是自动化的,不过需要在运行自动化脚本之前,手动更新一些配置,比如该使用哪个AMI镜像等。
- 自动化测试时间不会特别长 这里所说的特别长其实不容易定义,具体多长时间为长,都是相对而论。个人感觉,只要你觉得不用给各层测试做独立的jenkins任务(全都放在build中),仍然可以清晰的知道什么时候运行什么测试,什么测试出现了问题,即可。
- 环境之间的递进关系不明显 这种策略下,由于是手动选择和触发部署过程,所以一次代码更改可能不会被部署到所有环境中,可能只会被部署到某一个测试环境中用于测试。所以环境之间的递进(如下文中越来越接近产品环境的)只能体现它对应的部署任务里的一些配置参数上,比如说preprod环境的部署job用的是真实数据库,而QA环境的部署job用的是mock的数据。
B项目的策略及比较
而我曾经接触过的一些项目,同样为了便于说明,这里我们统称它为B项目,不管它的CI/CD工具用的是jenkins还是go.cd,它们都会是一种流水线(pipeline)的形式,如下图所示(没错,请叫我灵魂画师,<手动羞耻脸>):
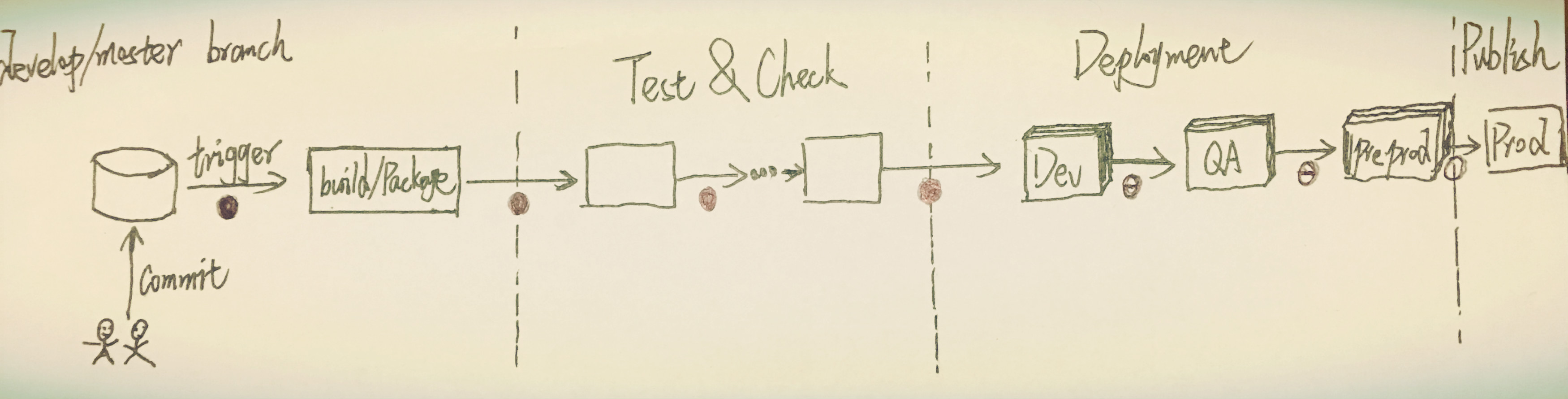
如上图所示,相对A项目的策略来说,这些jenkins任务分的更加细,中间的各层测试视具体项目而言可能包含单元测试、集成测试、回归测试、集成测试等等,然后就是将其部署到Dev环境(开发人员手动测试、验证的环境)。毋庸置疑,这里从开发人员提交代码到部署至Dev环境,包括测试的运行在内,都是自动化的。这意味着如果你的代码没有问题,你不需要做任何事,除了提交代码和看一下这个pipeline的状态。之后的几个环境,由于越来越接近产品环境,而且会提供给不同的人用于测试或者演示(showcase),所以很多时候需要对应的人手动的触发对应的部署/发布。当然,这样的部署/发布过程也是自动化,所以说在发布到产品环境之前,类似的部署/发布方式其实已经被验证过很多次了,而且是一次更改必须强制性地必须经过各个环境的测试和验证。
结合《持续交付》一书中提到的部署流水线的三个目标而言,我们来比较一下A项目和B项目用的这两种部署策略优缺点:
- 可视化 - 让软件的构建、部署、测试和发布过程对所有人可见,这一点对于合作至关重要。A项目这种分离的任务形式,其实不够直观,也不太能够让开发人员之外的业务人员、管理人员等直观地明白我们在哪里出现了问题,任务的划分也相对简单。B项目的这种策略,任务划分相对直观明了,任何人只要关注这条流水线,就大概知道应该是什么流程出现了问题。
- 及时反馈 - 持续交付的最大好处其实就是及时反馈了。而这一点在A和B上都有体现,任务的成功与失败都可以给出对应的反馈,告诉我们是否哪儿出了问题。不过A相对来说,反馈方式(可视化程度)更弱一点,反馈周期(集成周期较长)更长一点。
- 自动化 - 很明显,从上面两个图可以看出,B的自动化程度肯定是高于A的,无论是构建还是部署,A都需要去手动更改配置和手动触发。不过两种策略中间的实现毋庸置疑都是自动化的。
如果只从上面看,其实B项目的策略理应优于A项目的策略的。但是,很显然,“没那麼简单 就能去爱 别的全不看”。还记得我们说过A项目服务众多吗,A的采用这种策略很大一部分原因,个人猜测(还未经验实),一是重视任务之间的隔离性,二是为了便于管理各个服务之间依赖。比如,在A项目中,我想把之前feature1的某个测试环境里面的某个服务改为另外一个合适的版本,我只需要在部署时,将部署任务执行前的某个参数改为对应的endpoint就行,这在B项目策略中虽然也是可行的,但A项目的方式相当于在每次部署前都会提醒你这些参数的值,你可以决定是否修改。
当然,我个人觉得这与它们的git分支模型也不无几分关系。接下来就让我们来看看它们分别使用什么样的git分支模型。
A项目的git分支模型
A项目使用的git分支模型 - git flow(如果你还不了解这个概念,请阅读A successful Git branching model):
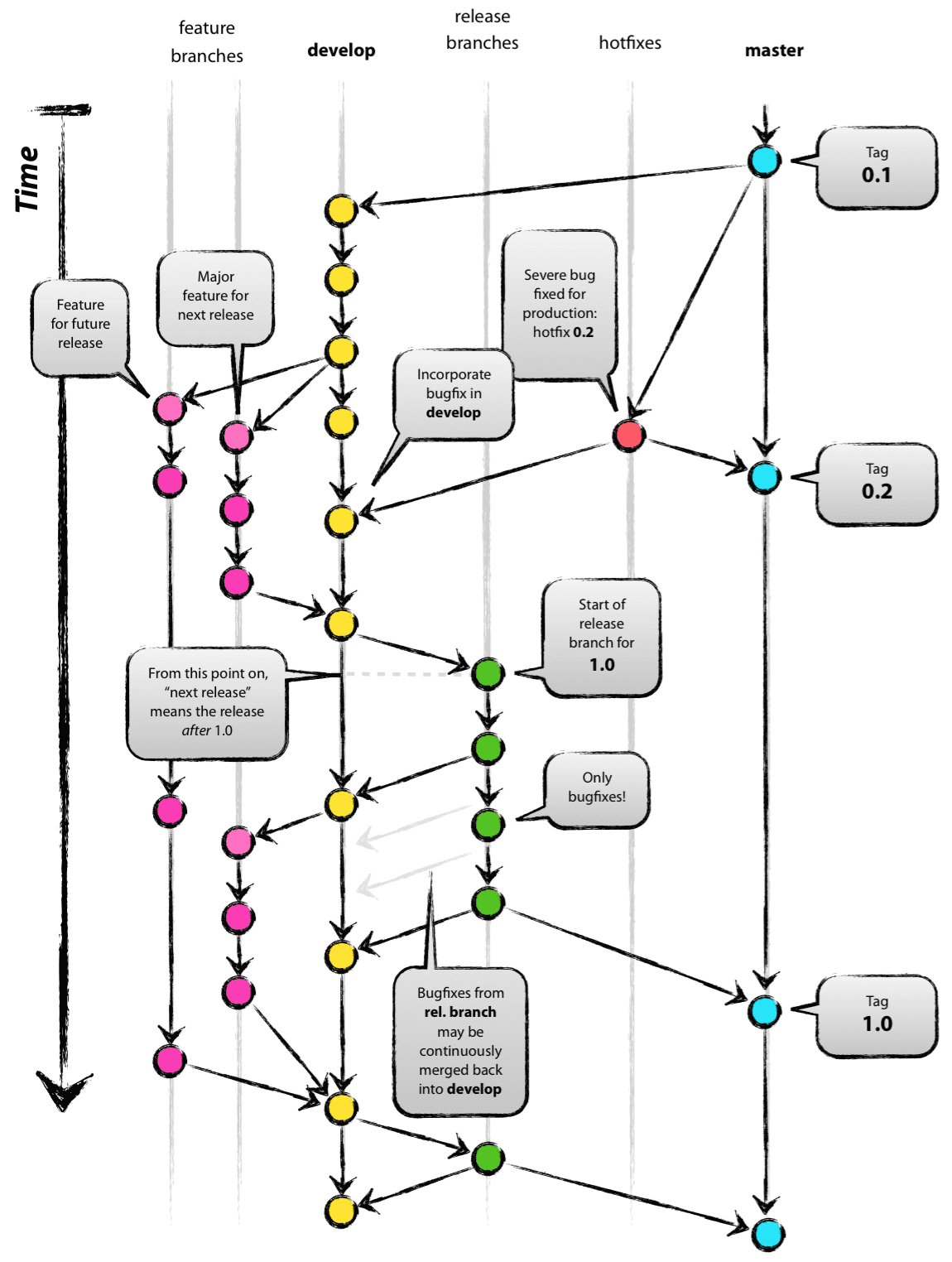
简单介绍一下的各种分支:
- master - 与产品环境代码保持一致的分支,也就是每次发布完成之后发布的功能分支就要合并于此,以保持master更新。
- develop - 开发的主分支,feature和release分支会基于此分支。
- feature - 具体要开发的功能的分支,完成后合并到develop。
- release - 用于发布新版本的分支,完成后合并到develop和master。
- hotfix - 用于紧急修复已发布的产品问题的分支,完成后合并到develop和master。
这种模型的话,理论上来说相对安全。但是一般feature分支都是需要用于开发一个较大的功能才做的分支,在此之上,我们还要建对应的故事卡(敏捷中,一个不可/不宜划分的需求单位)的分支,如下所示:
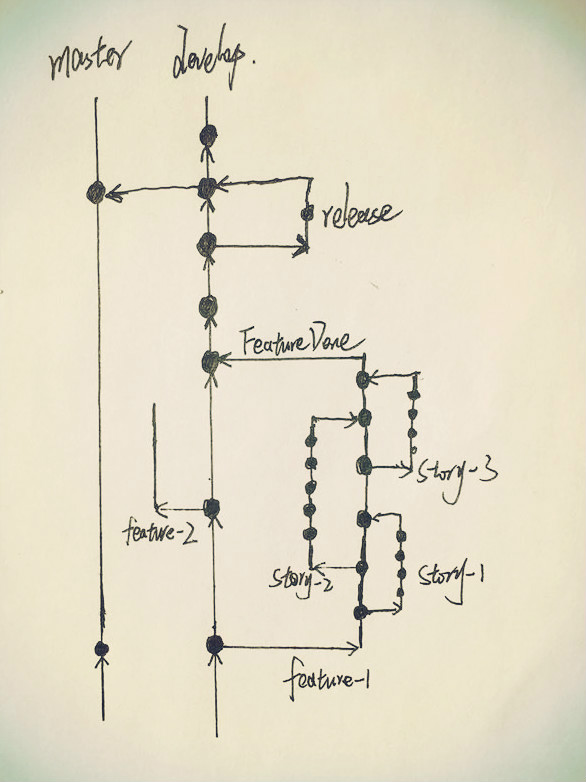
这么做的好处有:
- 隔离性比较好,更加安全 所有的功能都会有对应的分支,开发和测试工作不会互相干扰,发布进程也不会受其他未开发完的功能干扰。
- 分支职责明确 对应的分支做对应的事情,职责明确。
但是缺点也比较明显:
- 集成的周期太长 如果同时有几个大的功能在各自的分支上开发,每个功能的开发周期都不短的话,那之后他们之间的合并、集成工作将会十分痛苦。如果以《持续集成》这一本书中观点来看,这甚至算不上持续集成。
- 会有比较多的重复测试 完成分支的测试之后,在集成到主分支之后,还要重复一遍测试。自动化测试重复还可以接受,重复地手动的测试就比较烦人了。
- 结构相对复杂 分支较多,且存在层级关系(比如故事卡分支出自feature分支,feature分支出自develop分支)。
B项目的git分支模型
对应地,B项目,存在分支的话(我这么说,是因为也有不使用分支的真实项目),以我之前的某个离岸海外项目为例,会像如下图所示:
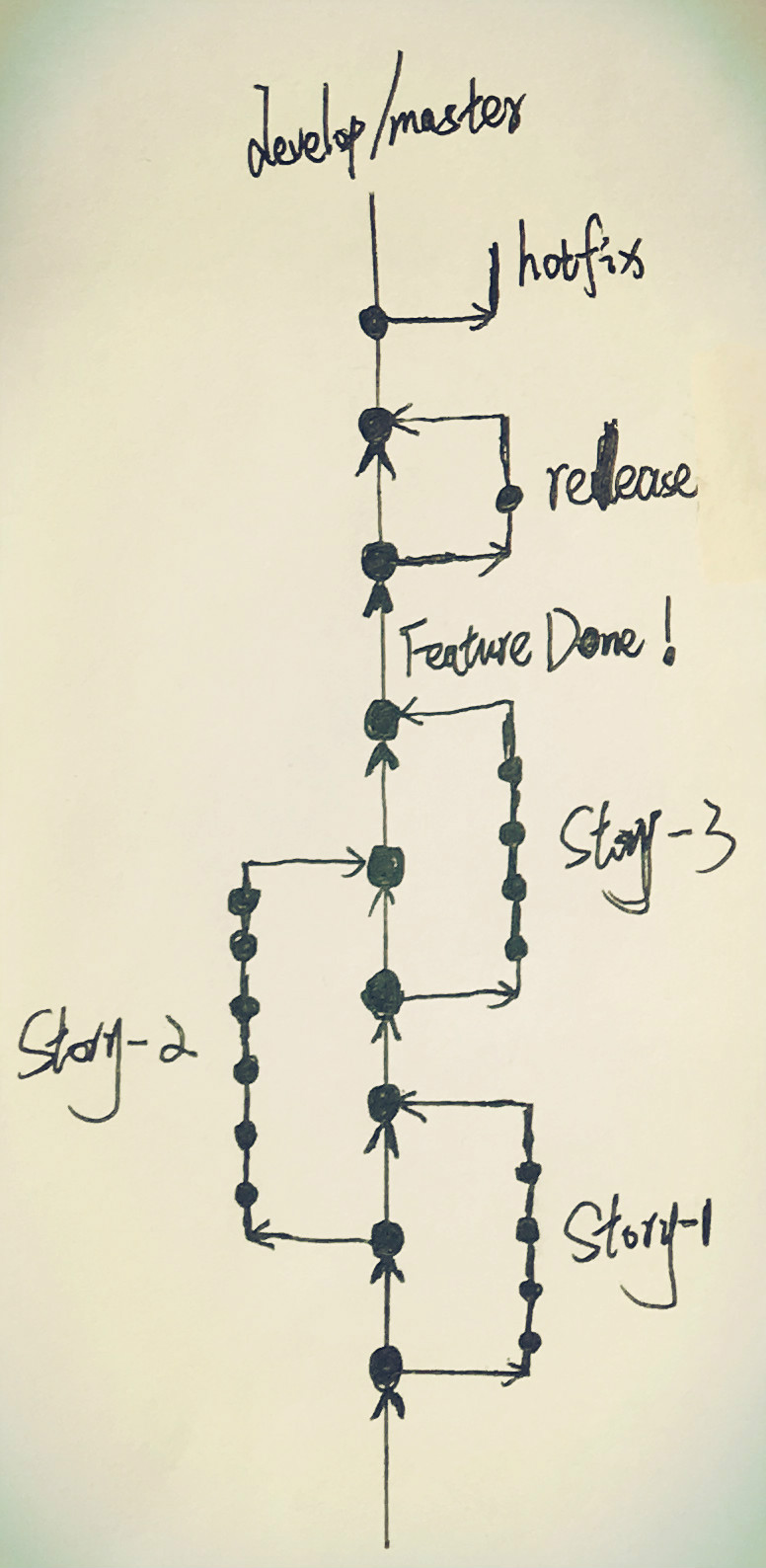
明显地,这种结构看起来简单很多。所有分支都是基于develop或者叫master这样的主分支。基于故事卡建分支,合并分支。
这么做有如下好处:
- 结构相对简单 所有分支的都是以故事卡为单位,结构简单。全部围绕一条主分支。
- 符合小步提交、持续集成思想 以一张故事卡为集成的最小单位,相对来说集成的周期短,反馈的速度也快,能够及早的遇到问题,从而及早的解决问题。
但是,金无足赤,它有时候也可能会有一些缺点:
- feature toggle的引入与测试 这种模型下,为了不让某些没有完成的功能影响已经完成的功能发布进程。在软件的设计初级以及后期测试,都需要把对应的feature toggle加入进来。也就是说,需要确保在各个环境中那些没有完成的功能应该处于disable状态。这无疑增加一部分工作量,也会带来一点风险。不过,这种工作量和风险大部分团队都会承担,毕竟如果计划分析的合理,发生的几率还是挺小的。
- 隔离性较差 引入feature toggle的很大一部分原因就是为了弥补隔离性上的缺陷。但是如果你主张:所有的分支终究是要合并到一个分支、发布成一个产品的,那这一缺点其实并不重要。
总结
当然,还有很多其他的策略和分支模型(或者没有分支的模型),我这里不再探讨过多。其实就我目前提到的AB两种,甚至可以交叉使用(比如A项目情况用B项目的策略),具体如何采用以及何时适合采用,这个问题可以留给有心的读者自己思考。
最后我想说,这几种方式虽然各有优缺点,但相比更加传统的缺乏自动化的方式而言,已然进步太多。

